This article is intended for informational purposes only and does not supersede or replace the official documentation provided by OpenText. It serves as supplementary guidance to assist with common challenges that may arise during installation and upgrades. For authoritative instructions and compliance requirements, refer to OpenText’s official documentation.
The capture component used in conjunction with OpenText Vendor Invoice Management for SAP Solutions (SAP VIM) is usually Intelligent Capture for SAP Solutions (short: IC4S; on premise) or Core Capture for SAP Solutions (short: CC4S; hosted in the OpenText Cloud).
Continuous feedback allows the capture component of VIM to read and interpret more and more incoming .pdf-documents fully or partly. In some systems, however, it is simply never switched on. As a result, the automatic recognition of data on the documents never improves and a high manual validation effort is required. This is not only annoying but also expensive.

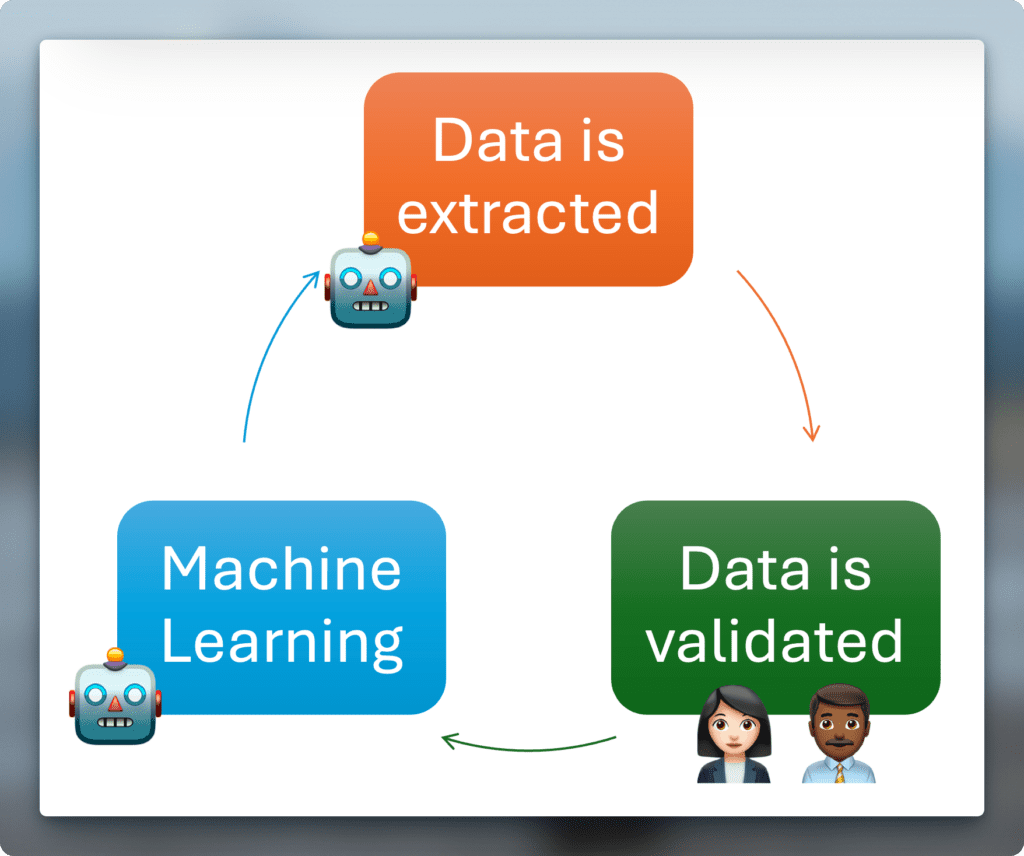
How does the learning work?
In simple terms, the process for continuous learning works like this:
- The system (IC4S or CC4S) extracts as much data as possible from the document
- The extracted data is corrected and supplemented by users in the validation client.
- The corrected results are sent back to the capture component via the so-called feedback link, which expands the set of rules for extracting data and generally delivers a better result for the next similar document.
What is an Archive Link Document Type?
An Archive Link Document Type refers to a classification used for documents that are stored in an external archive system but linked to SAP transactions via SAP ArchiveLink. ArchiveLink is an SAP technology that enables the connection of external document management systems (DMS) to SAP applications.
In the simplest case, there is one archive link document type in a VIM project for storing, for example invoices, let’s call it “ZINVOICE”. Whether the learning is executed or not depends on the settings assigned for this archive link document type.
In VIM projects, usually one or more archive link document types are created for both invoicing and non-invoicing processes. These allow you to create your own scenarios independently of the document types supplied with the product.
My recommendation here is always to create your own archive link document types. This makes customization easier and you don’t run the risk of accidentally resetting all possible settings during the next VIM upgrade. However, this also opens the door for the customizing mistake which I describe in this article.
Is my system learning or is it standing still?
You can find out in just a few minutes whether your system is learning, or at least is encouraged to learn (in addition to this setting, there are also other reasons that can prevent learning).
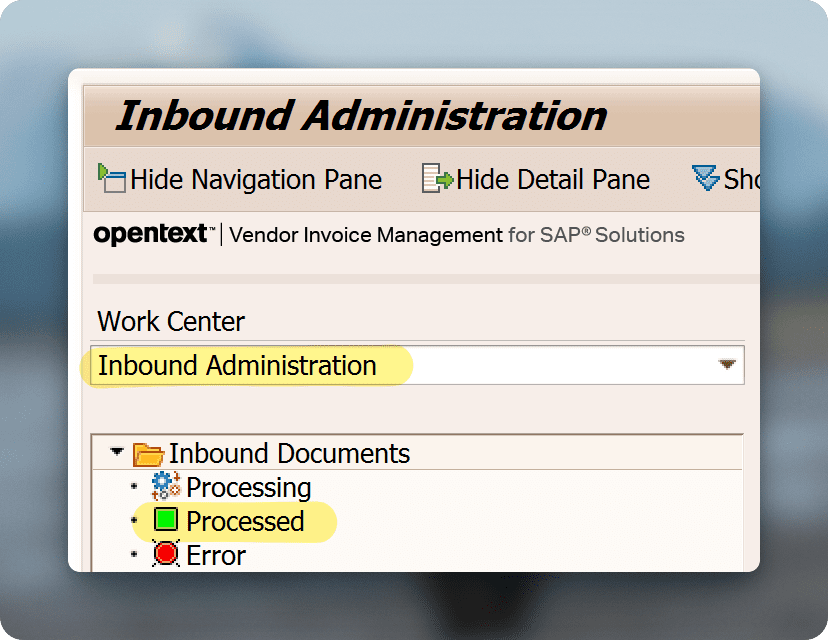
First we find out which Archive Link document type we are using, the quickest way to do this is in transaction /OTX/PF03_WP (VIM Central Workplace) in the work center Inbound administration.
/otx/pf03_wpSelect the “Processed” note and select the line of a recently processed document.
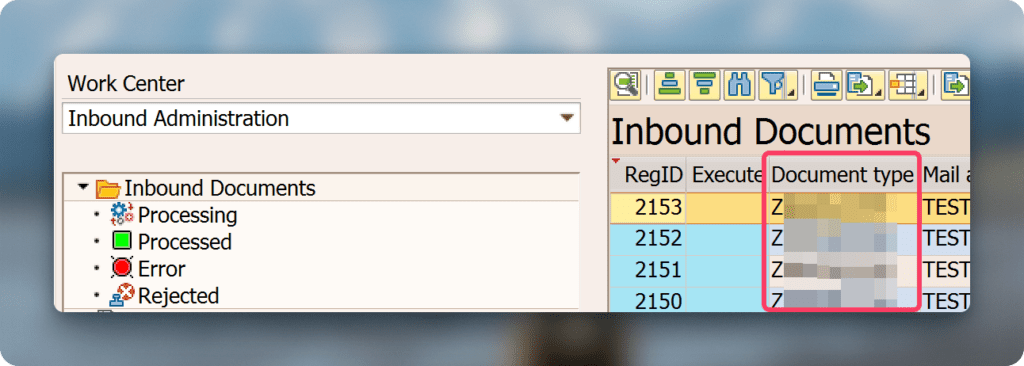
In the line you can scroll to the right until you see the column “Document type”. Note all the Document types you are using. For example “ZINVOICE”.
The next step ist to check the customizing in /OTX/PF00_IMG.
/otx/pf00_imgNavigate to Inbound Configuration > Capture > Feedback:
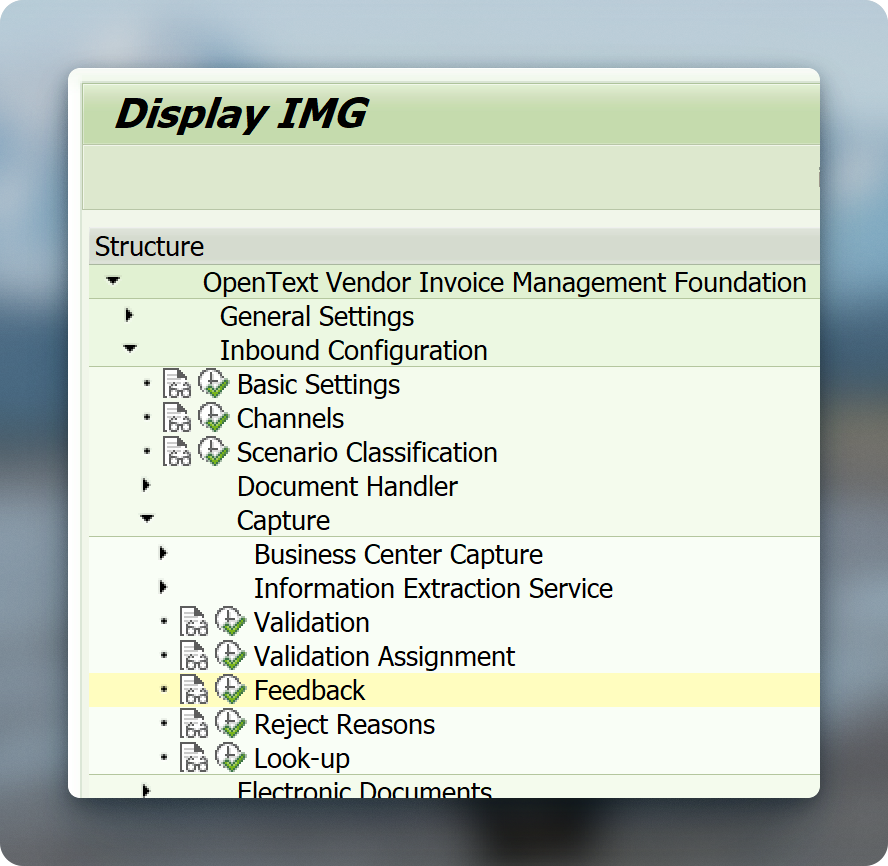
In the table you should see all active archive link document types you are using with an active checkbox next to them:
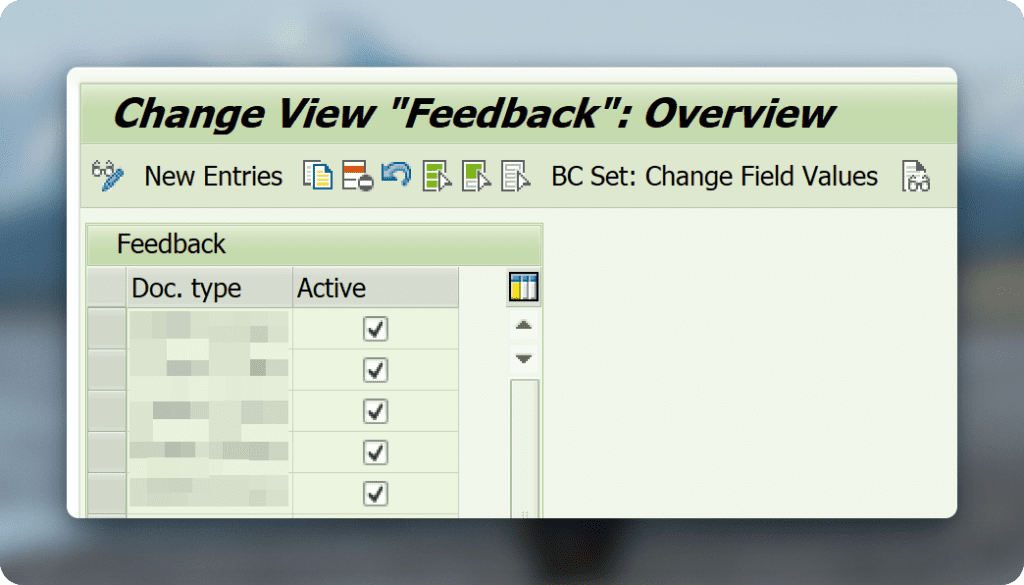
In case you archive link document type is missing here there will be no learning taking place after validating documents. This means that your validation process does not generate a sustainable learning effect but is only valid for the current document.
My learning is not activated, how do I solve the problem?
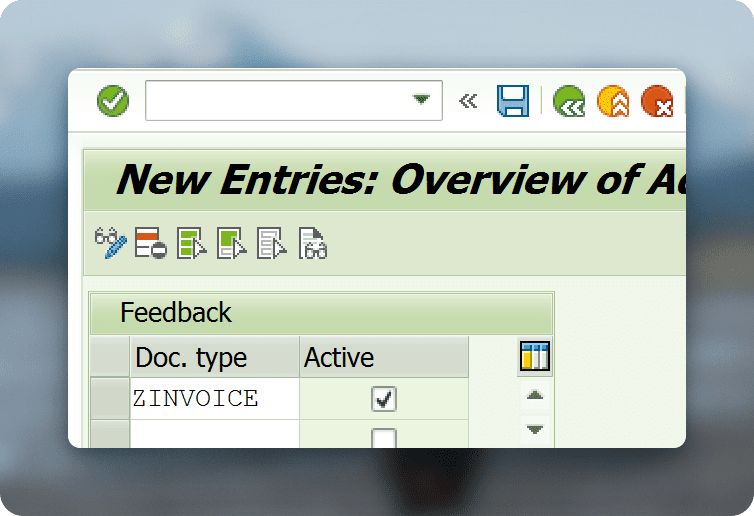
The problem is quickly solved. Add the missing entry in the development system, test, transport and the issue is resolved (learning will only take place for newly processed documents).
Why didn’t we realize this earlier?
In the case of non-invoice-related document processes, the problem is usually immediately apparent because without learning results, not a single field (with the exception of business entities) is recognized and therefore an exorbitantly high validation effort is required.
The situation is different for invoice-related processes, where the product standard already provides basic recognition results, which are then improved by validation. Therefore you already have a basis of recognition results and do not initially notice that the feedback is missing.
Conclusion
This setting is very simple but unfortunately easy to overlook. The system does not complain about the missing setting and everything initially appears to be working. If this article has helped you to resolve a big problem in a simple way, I would be happy if you share it!


Leave a Reply